Red Hat Pipelines con Vite

Intro
OpenShift offre diverse opzioni per creare e distribuire applicazioni e tra questi ci sono:
- templates: si tratta del modo più semplice per descrivere tutti gli oggetti necessari per rilasciare effettivamente un’applicazione in OpenShift (tipicamente, ma non esclusivamente, DeploymentConfig, Service, Route e forse BuildConfig) e avere il pieno controllo sulla loro configurazione;
- Pipeline Jenkins: sì, puoi usare il buon vecchio Jenkins per implementare il tuo processo CI/CD su OpenShift.
In questo caso, vogliamo però realizzare una pipeline che permetta di utilizzare del codice sorgente disponibile su un repository qualsiasi e di avviare il deploy dell’applicazione all’interno del cluster in maniera del tutto automatica.
Per farlo, è sufficiente utilizzare le Red Hat OpenShift Pipelines, uno strumento potente tanto quanto complesso, che dietro le quinte utilizza Tekton, uno dei progetti open source più utilizzati in ambito CI/CD.
Andiamo per gradi: lo scenario per ripetere l’esperimento che verrà mostrato e che andremo a descrivere è abbastanza semplice:
- Il codice sorgente per l’applicazione si trova in un repository GitHub pubblico (o privato);
- L’immagine del container creata durante il processo di compilazione viene inviata a un registry di immagini (come Quay) pubblico (o privato);
- Disponiamo di un cluster OpenShift attivo e funzionante da qualche parte, pronto per eseguire l’applicazione. Se non hai cluster a disposizione, puoi sempre utilizzare OpenShift Local!
Per il caso di esempio, useremo un’applicazione scritta in Vite.js (il repository è in fondo nelle risorse utili), ma è possibile utilizzare qualsiasi altro esempio che abbia un Dockerfile valido e utilizzabile su OpenShift!
Cos’è Tekton
Come descritto nel sito web del progetto open source Tekton:
Tekton è un framework open source potente e flessibile per la creazione di sistemi CI/CD, che consente agli sviluppatori di creare, testare e distribuire tra provider cloud e sistemi on-premise.
Red Hat OpenShift Pipelines è una soluzione CI/CD cloud-native completamente basata sulle risorse Kubernetes che utilizza i concetti e gli elementi costitutivi di Tekton per automatizzare le distribuzioni su più piattaforme astraendo i dettagli d’implementazione sottostanti. Tekton introduce una serie di Custom Resource Definitions (CRD) standard per la definizione di pipeline CI/CD portabili tra le distribuzioni Kubernetes.
Concetti
Concetti che definiscono la pipeline
- Pipeline: la definizione della pipeline e le attività che dovrebbe svolgere
- Task: un numero di passaggi riutilizzabile e liberamente accoppiato che esegue un’attività specifica (ad esempio, la creazione di un’immagine del container)
Concetti che gestiscono la pipeline
- PipelineRun: l’esecuzione e il risultato dell’esecuzione di un’istanza di una pipeline, che include una serie di TaskRun
- TaskRun: l’esecuzione e il risultato dell’esecuzione di un’istanza di un Task
Concetto per aiutare la pipeline a funzionare correttamente
- PipelineResource: risorse di questo tipo servono a fornire gli strumenti per poter lavorare e che sono fondamentali lungo tutto il flusso di lavoro, per esempio, un repository Git o un’immagine da utilizzare.
Installazione dell’Operator
Prima ancora di pensare di utilizzare il framework OpenShift Pipelines, è necessario ovviamente installarlo nel
cluster; Red Hat fornisce un operatore per semplificare il processo di installazione.
Andiamo nella console Web di OpenShift e, attraverso la prospettiva amministrativa, seleziona Operators → OperatorHub dal menu di navigazione a sinistra e quindi cerca l’operatore Red Hat Pipelines; a questo punto, fai clic sul riquadro e quindi sul successivo pulsante Installa.
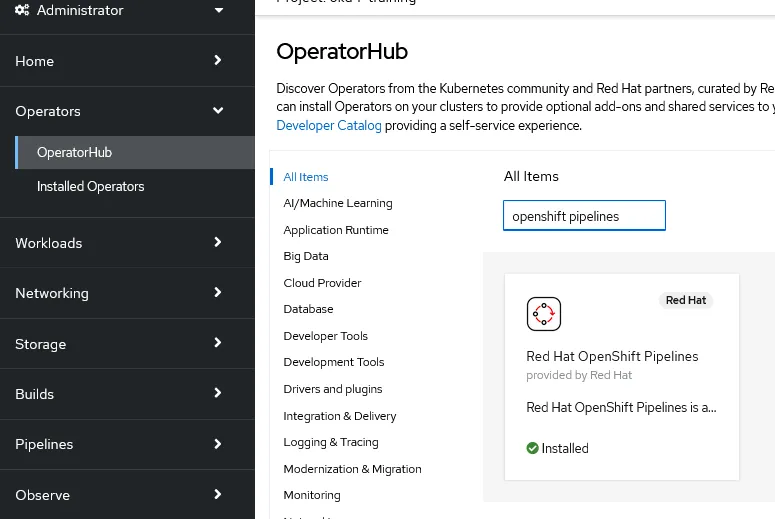
Manteniamo le impostazioni predefinite e proseguiamo con l’installazione, attendiamo che sia completata e vedremo una nuova voce nel menù di sinistra della prospettiva Developer, relativa alle Pipelines:
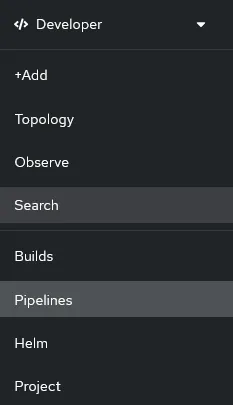
Con questi pochi semplici passaggi abbiamo installato OpenShift Pipelines e ora possiamo procedere a utilizzare questo framework basato su Tekton per creare una pipeline per costruire e distribuire applicazioni, ma sii paziente: abbiamo ancora bisogno di un paio di passaggi preliminari per mettere le basi.
Configurazione di registry per le immagini e per il codice sorgente
L’immagine, una volta che sarà stata generata a partire dal codice sorgente, verrà pushata sia nel registry interno di OpenShift, sia su uno esterno, come forma di backup e/o rilascio: questo vuol dire che sarà necessario accedervi dal cluster con i giusti permessi di scrittura e lettura.
Nel caso di Quay.io, è sufficiente creare un account (gratuito), creare un repository e poi aggiungere un robot account ai permessi con i permessi di lettura e scrittura.
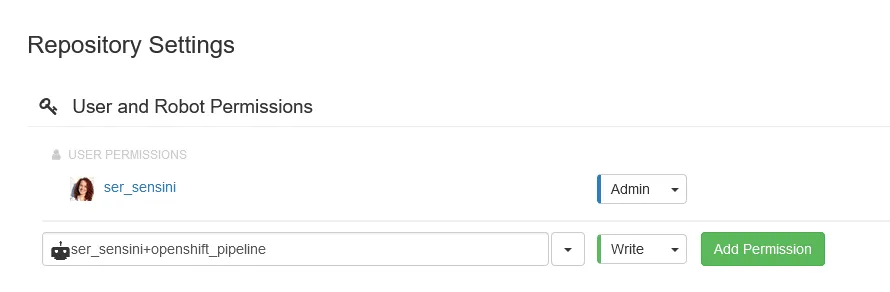
A questo punto, cliccando sull’account appena creato, selezioniamo la sezione relativa a Kubernetes e scarichiamo il Secret che contiene il pull secret che permette all’utente fittizio di collegarsi al repository e di operare:
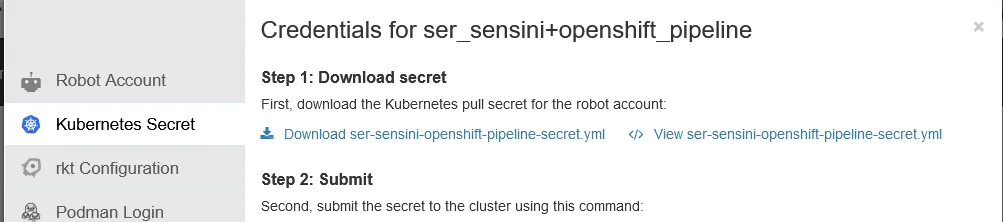
Prima di eseguire le pipeline OpenShift, dobbiamo assicurarci che siano disponibili le autorizzazioni corrette per accedere al codice e al registry che ospita l’immagine, e il modo per farlo è configurare un ServiceAccount su OpenShift in modo appropriato e collegare i Secret contenenti le informazioni giuste.
Partiamo dal codice sorgente: se si trova su un repository pubblico, non dobbiamo compiere ulteriori passaggi, e possiamo proseguire. Se invece il repository è privato, possiamo creare un Secret che ci permetta di inserire le informazioni per accedere al codice con il seguente comando:
oc create secret generic <YOUR_GITHUB_SECRET_NAME> \
--from-literal=username=<YOUR_GITHUB_USERNAME> \
--from-literal=password=<YOUR_GITHUB_PERSONAL_ACCESS_TOKEN> \
--type=kubernetes.io/basic-auth
#oc annotate secret <YOUR_GITHUB_SECRET_NAME> "tekton.dev/git-0=https://github.com"
Stesso discorso vale per il registry che ospiterà l’immagine: se il repository è pubblico, possiamo proseguire, altrimenti dovremo creare un Secret che ci permetta di inserire le informazioni per accedere in lettura e scrittura al registry con il seguente comando:
oc create secret docker-registry <YOUR_REGISTRY_SECRET_NAME> \
--docker-server=<YOUR_REGISTRY_URL> \
--docker-username=<YOUR_REGISTRY_USERNAME> \
--docker-password=<YOUR_REGISTRY_PASSWORD>
Aggiungere i permessi
Proseguiamo con il ServiceAccount: quando installi l’operatore, viene creato un ServiceAccount chiamato pipeline per eseguire correttamente le attività e le pipeline di Tekton, quindi gli concederemo le autorizzazioni appropriate.
Aggiungiamo quindi i permessi che permetteranno al ServiceAccount pipeline di operare: con il primo comando, specifichiamo che questo “utente” potrà gestire e accedere a tutte le risorse e i container presenti nei nodi computazionali. Chiaramente, si tratta di un permesso piuttosto “ampio”, quindi dovrebbe essere utilizzato solo per attività seguite da chi amministra il cluster.
Il secondo comando permette di modificare le risorse nel progetto, ma solamente quelle applicative: non potrà quindi vedere o modificare i ruoli degli utenti o dei gruppi, e questo gli servirà per poter avviare Deployment, Service e molto altro.
Con il terzo e il quarto comando andiamo a far riferimento al Secret creato in precedenza relativo al robot account del registry e lo colleghiamo al Serviceaccount pipeline, così che abbia le informazioni per agire con quel repository.
oc adm policy add-scc-to-user privileged -z pipeline
oc adm policy add-role-to-user edit -z pipeline
oc secrets link pipeline <YOUR_REGISTRY_SECRET_NAME>
oc secrets link default <YOUR_REGISTRY_SECRET_NAME> --for pull
È necessario un ultimo passaggio preparatorio prima di poter effettivamente eseguire le pipeline OpenShift.
In Tekton ogni Task viene eseguito nel proprio container quindi, per consentire a diversi Task di condividere i dati (ad esempio: un’attività recupera il codice sorgente da un repository e un’altra attività crea l’applicazione dal codice sorgente), dobbiamo inserire un volume nell’equazione.
Andiamo quindi a definire una PVC utilizzando un oggetto simile a quello seguente, anche molto dipende dalla StorageClass e in generale dal provisioner utilizzato:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pipeline-build
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 500Mi
Definizione della pipeline
Dopo aver completato questi step di preparazione, ora possiamo creare la nostra pipeline. Puoi dare un’occhiata
all’esempio nel file seguente: questo descrive quattro passaggi, eseguite in sequenza, che servono per ottenere il
codice sorgente da un repository GitHub, creare un’immagine del container a partire da un Dockerfile, eseguirne il
push in un registry, avviare il deploy su OpenShift e infine esporre l’applicazione con una route per l’accesso esterno.
---
apiVersion: tekton.dev/v1beta1
kind: Task
metadata:
name: vite-deploy-example
spec:
workspaces:
- name: source
steps:
- name: ls
image: image-registry.openshift-image-registry.svc:5000/openshift/cli:latest
workingDir: /workspace/source
command: ["/bin/bash", "-c"]
args:
- |-
echo Listing files
pwd
ls -la
echo -----------------------------------
---
apiVersion: tekton.dev/v1alpha1
kind: PipelineResource
metadata:
name: vite-with-docker
spec:
type: git
params:
- name: url
value: https://github.com/serenasensini/Vite-with-Docker
- name: revision
value: master
---
apiVersion: tekton.dev/v1alpha1
kind: PipelineResource
metadata:
name: vite-example-image
spec:
type: image
params:
- name: url
value: quay.io/ser_sensini/vite-example:0.0.1-build
---
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: vite-example
spec:
params:
- default: vite-example
description: name of the application to deploy
name: APP_NAME
type: string
- default: https://github.com/serenasensini/Vite-with-Docker
description: url of the git repo for the code of deployment
name: GIT_REPO
type: string
- default: main
description: revision to be used from repo of the code for deployment
name: GIT_REVISION
type: string
- default: quay.io/ser_sensini/vite-example:0.0.1-build
description: image to be built from the code
name: IMAGE
type: string
- default: '5173'
description: Port on the container that the service should direct traffic to.
name: SERVICE_PORT
type: string
tasks:
- name: fetch-repository
params:
- name: url
value: $(params.GIT_REPO)
- name: revision
value: $(params.GIT_REVISION)
- name: subdirectory
value: ''
- name: deleteExisting
value: 'true'
taskRef:
kind: ClusterTask
name: git-clone
workspaces:
- name: output
workspace: workspace
- name: build-image
params:
- name: TLSVERIFY
value: 'false'
- name: IMAGE
value: $(params.IMAGE)
runAfter:
- fetch-repository
taskRef:
kind: ClusterTask
name: buildah
workspaces:
- name: source
workspace: workspace
- name: deploy
params:
- name: SCRIPT
value: >-
oc new-app --name=$(params.APP_NAME) --image=$(params.IMAGE)
--as-deployment-config
runAfter:
- build-image
taskRef:
kind: ClusterTask
name: openshift-client
- name: expose-route
params:
- name: SCRIPT
value: oc expose service/$(params.APP_NAME) --port $(params.SERVICE_PORT)
runAfter:
- deploy
taskRef:
kind: ClusterTask
name: openshift-client
workspaces:
- name: workspace
Scaviamo un po’ nell’anatomia della pipeline; all’inizio della sezione del codice, ci sono 2 aree:
- workspace, che definisce un’area di lavoro che può essere associata a uno storage permanente una volta eseguita la pipeline;
- params, dove sono definiti tutti i parametri che possono essere accettati dalla pipeline, con i loro valori di default, se presenti.
---
# ...
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: vite-example
spec:
params:
...
tasks:
...
workspaces:
- name: workspace
Analizziamo i Task uno a uno: quello chiamato fetch-repository, che puoi trovare nel codice sottostante, è responsabile della clonazione del repository del codice sorgente; ha i propri parametri, il cui significato dovrebbe essere abbastanza chiaro e una sezione workspaces che lega l’output alla cartella che è stato definita in precedenza tramite lo storage. Da notare inoltre che l’attività fa riferimento al clone git ClusterTask: i ClusterTask sono attività comunemente utili a livello di cluster implementate e rese disponibili da Red Hat OpenShift, in modo che tu possa semplicemente riutilizzarle senza reinventare la ruota.
...
tasks:
- name: fetch-repository
params:
- name: url
value: $(params.GIT_REPO)
- name: revision
value: $(params.GIT_REVISION)
- name: subdirectory
value: ''
- name: deleteExisting
value: 'true'
taskRef:
kind: ClusterTask
name: git-clone
workspaces:
- name: output
workspace: workspace
...
Il Task chiamato build-image è responsabile della creazione e del push dell’immagine nel registry, in base al valore del parametro $(params.IMAGE); nel caso di esempio questo è quay.io/ser_sensini/vite-example:0.0.1-build, quindi cercherà di eseguire il push al registry di Quay.io e creare un’immagine con il nome e il tag specificato.
Si basa su un ClusterTask che usa buildah, uno strumento molto simile a Podman, che costruisce l’immagine sulla base di un Dockerfile; notare la sezione runAfter che indica alla pipeline di eseguire l’attività solo dopo il completamento dell’attività fetch-repository.
...
tasks:
- name: build-image
params:
- name: TLSVERIFY
value: 'false'
- name: IMAGE
value: $(params.IMAGE)
runAfter:
- fetch-repository
taskRef:
kind: ClusterTask
name: buildah
workspaces:
- name: source
workspace: workspace
...
Il Task deploy è responsabile del rilascio e dell’avvio dell’immagine, creata nel passaggio precedente, in OpenShift. Si noti che è basato su un altro ClusterTask, openshift-client, che consente di utilizzare la riga di comando oc all’interno della pipeline; questo serve per permette l’utilizzo del comando oc new-app, che andrà a creare un Pod con il relativo controller DeploymentConfig a partire dall’immagine specificata.
tasks:
- name: deploy
params:
- name: SCRIPT
value: >-
oc new-app --name=$(params.APP_NAME) --image=$(params.IMAGE)
--as-deployment-config
runAfter:
- build-image
taskRef:
kind: ClusterTask
name: openshift-client
Infine l’attività expose-route è responsabile di creare una Route in OpenShift in modo che l’applicazione sia accessibile tramite browser con un protocollo HTTP.
tasks:
- name: expose-route
params:
- name: SCRIPT
value: oc expose service/$(params.APP_NAME) --port $(params.SERVICE_PORT)
runAfter:
- deploy
taskRef:
kind: ClusterTask
name: openshift-client
Ora che abbiamo progettato e implementato una pipeline OpenShift, probabilmente vorremo utilizzarla, e possiamo farlo in un paio di modi: eseguire una pipeline tramite la riga di comando con la CLI di Tekton Pipelines o eseguire una pipeline utilizzando la GUI di OpenShift.
Rimaniamo sulla console di OpenShift, e selezioniamo la voce Pipelines dal menù di sinistra: una volta importato il file precedente, vedremo all’interno dell’elenco una nuova voce, relativa a quanto definito. Clicchiamo sul dettaglio della pipeline e clicchiamo su “Actions”, in alto a destra: questo ci permetterà di avviare la pipeline ed eseguire i diversi step previsti, che verranno mostrati con il relativo stato sul dettaglio di sinistra.
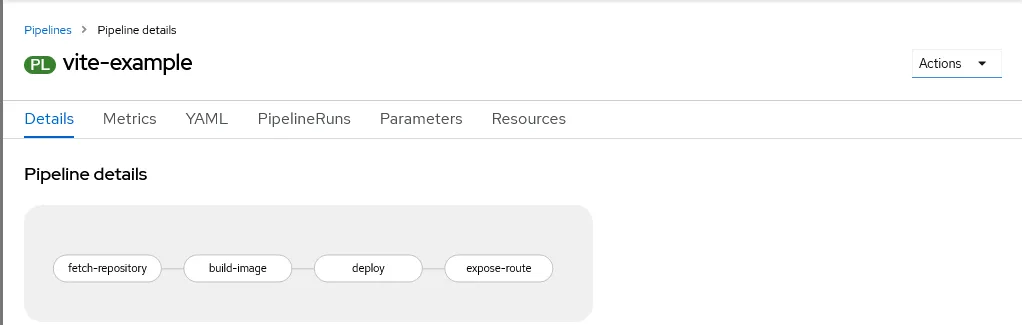
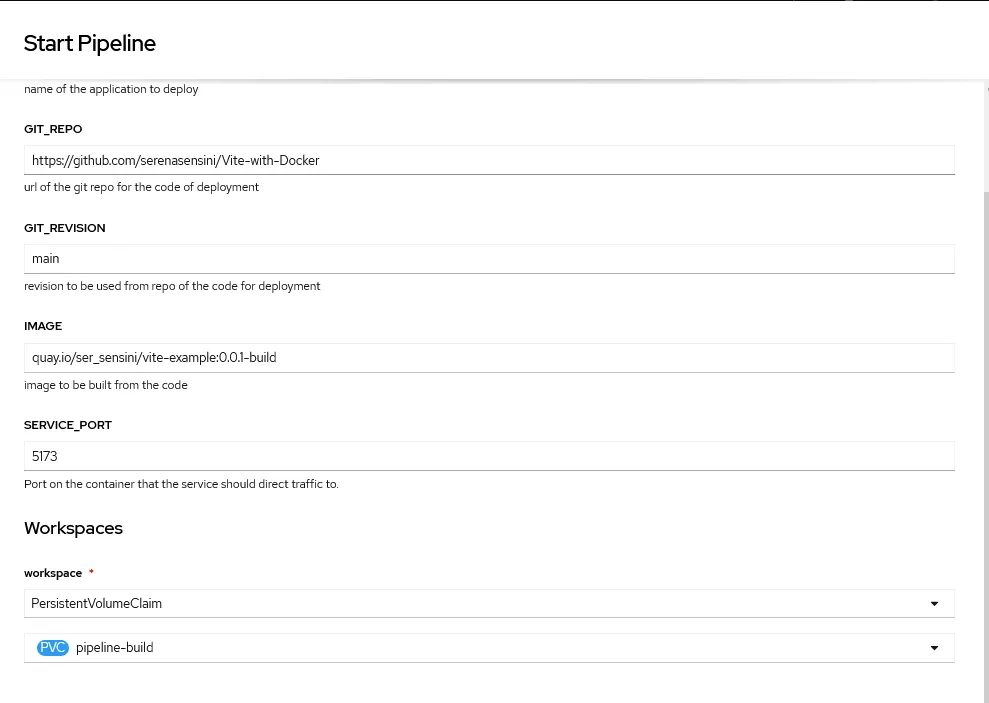
Avviando la pipeline, verrà creato un oggetto PipelineRun, che comportano una serie di TaskRun: ognuno di questi corrisponde a ogni Task descritto all’interno della Pipeline complessiva. Clicchiamo su “Start” tramite Actions e compiliamo i diversi campi, che corrispondono ai parametri definiti nella Pipeline: non ci dimentichiamo di associare al workspace il volume creato in precedenza, per permettere ai diversi Task di condividere i dati prodotti:
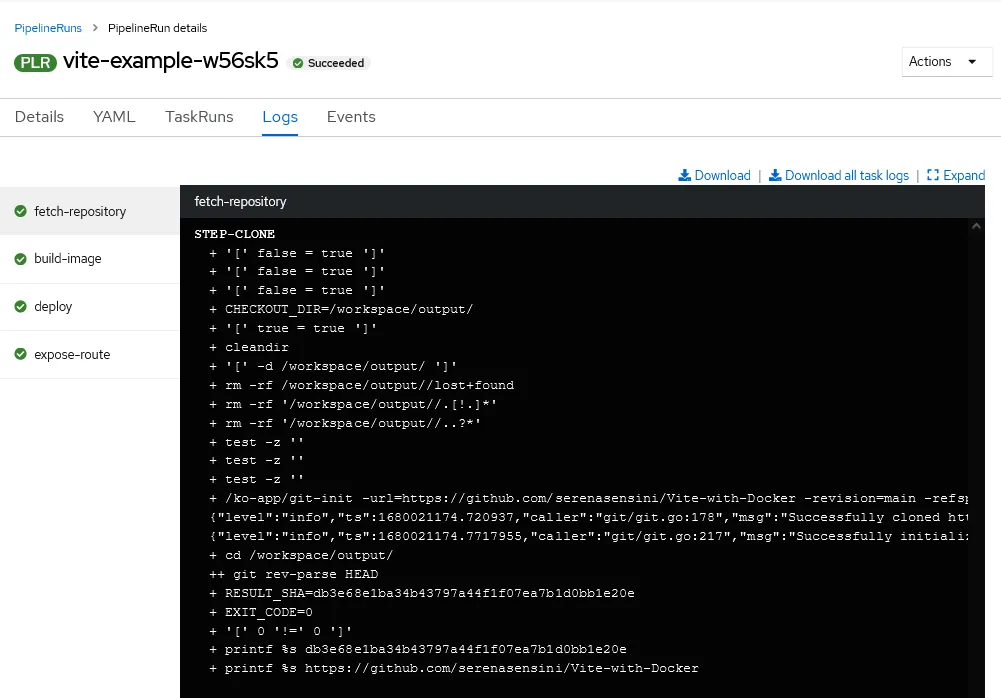
Per monitorare lo stato di esecuzione dei diversi Task, è possibile cliccare sui singoli riquadri di dettagli e vedere i log relativi ai singoli container.
Al termine dell’esecuzione, troveremo l’applicazione nella topologia del progetto, e potremo accedervi tramite la Route:

Questo naturalmente è un esempio molto semplice, ma può essere esteso ad altri casi d’uso, che coinvolgono Task più complessi, piuttosto che un’applicazione diversa o un tipo di risorse differenti; questo articolo vuole essere solo una panoramica di cosa fare per utilizzare il framework OpenShift Pipelines per costruire una pipeline!
Risorse utili
- Codice sorgente dell’applicazione Vite
- Docker - per cominciare bene con Docker e Kubernetes


