La resilienza in OpenShift
Intro
OpenShift è una straordinaria piattaforma per la gestione dei container, che fornisce la potenza di Kubernetes con una serie di funzionalità che ne permettono la distribuzione e l’utilizzo sia su infrastrutture on-premise che su un ambiente cloud pubblico.
Ora, con OpenShift 4.10, è diventato semplicissimo creare un cluster: ci sono diversi installer o soluzioni che possiamo utilizzare all’interno del nostro ambiente in cloud e, voilà, questo si occupa (quasi) di tutto: creare e configurare i nodi, installare il prodotto e renderlo pronto per l’uso. Niente male, no?
Alla luce di tutta questa automazione, la domanda che può sorgente è: “cosa succede quando si prova a distruggere OpenShift?”
In questo articolo, vediamo cosa vuol dire testare la resilienza di OpenShift, passando per il concetto di Machine e Machinset, e facendo dei test: proviamo a distruggere parte del cluster, e vediamo cosa succede.
Test #1
Supponiamo di avere un tipico cluster OpenShift (su AWS) con la seguente configurazione: 3 nodi master e 3 nodi worker configurati tramite delle semplici Machine, di cui possiamo recuperare le informazioni tramite il comando oc get nodes (avendo i permessi di cluster-admin):
$ oc get nodes
>>>
NAME STATUS ROLES AGE
ip-xxx-yyy-zzz-10.eu-central-1.compute.internal Ready worker 2d
ip-xxx-yyy-zzz-121.eu-central-1.compute.internal Ready worker 2d
ip-xxx-yyy-zzz-233.eu-central-1.compute.internal Ready worker 2d
ip-xxx-yyy-zzz-193.eu-central-1.compute.internal Ready master 2d
ip-xxx-yyy-zzz-94.eu-central-1.compute.internal Ready master 2d
ip-xxx-yyy-zzz-100.eu-central-1.compute.internal Ready master 2d
Come primo test, andiamo a distruggere uno dei nodi master e rispondere alla domanda: “Cosa succede?”
Ci sono alcuni modi per compiere questo test: distruggere l’istanza su cui gira il nodo o anche renderla inaccessibile agli altri master cambiando le configurazioni di rete. In questo caso, eseguiamo un test semplice e distruggiamo la risorsa che si occupa di gestire il nodo, ossia la Machine.
Le Machine sono degli oggetti che descrivono una risorsa che incapsula e definisce un nodo. In altre parole, rappresenta la macchina virtuale, o l’istanza con le relative risorse in termini di CPU, memoria e storage.
I nodi, quindi, rappresentano una Machine configurata per l’utilizzo con OpenShift, ovvero un’istanza che contiene i servizi necessari per eseguire i pod ed è gestita dai componenti master.
Le differenze sorgono a livello di astrazione: un nodo in OpenShift è esattamente la stessa cosa rispetto ad un nodo in Kubernetes e normalmente ci si riferisce all’astrazione di un “nodo” worker/master quando si parla di un “cluster”. L’astrazione del nodo esiste solo all’interno dei limiti di un cluster in esecuzione.
Una Machine è un’astrazione introdotta dalla definizione di Cluster API per permettere a chi definisce l’infrastruttura host richiesta di eseguire i
nodi utilizzando le specifiche della macchina.
Quindi troviamo tutte le Machines eseguendo il seguente comando:
$ oc get machines --all-namespaces
>>>
NAMESPACE NAME PHASE TYPE REGION ZONE AGE
openshift-machine-api my-cluster-master-0 Running m5.xlarge eu-central-1 eu-central-1b 2d
openshift-machine-api my-cluster-master-1 Running m5.xlarge eu-central-1 eu-central-1b 2d
openshift-machine-api my-cluster-master-2 Running m5.xlarge eu-central-1 eu-central-1b 2d
openshift-machine-api my-cluster-worker-eu-central-1b-xxxxx Running c5.4xlarge eu-central-1 eu-central-1b 2d
openshift-machine-api my-cluster-worker-eu-central-1b-yyyyy Running c5.4xlarge eu-central-1 eu-central-1b 2d
openshift-machine-api my-cluster-worker-eu-central-1b-zzzzz Running c5.4xlarge eu-central-1 eu-central-1b 2d
Per distruggere dunque un nodo master, e quindi la relativa istanza, andiamo ad eseguire il comando:
$ oc delete machine my-cluster-master-0
>>>
machine.machine.openshift.io "my-cluster-master-0" deleted
E cosa succede dopo che ho distrutto uno dei nodi master?
Niente.
Come visibile, OpenShift non ha creato un nuovo master, ma sta lavorando con soli due:
$ oc get nodes
>>>
NAME STATUS ROLES AGE
ip-xxx-yyy-zzz-10.eu-central-1.compute.internal Ready worker 2d
ip-xxx-yyy-zzz-121.eu-central-1.compute.internal Ready worker 2d
ip-xxx-yyy-zzz-233.eu-central-1.compute.internal Ready worker 2d
ip-xxx-yyy-zzz-193.eu-central-1.compute.internal Ready master 2d
ip-xxx-yyy-zzz-94.eu-central-1.compute.internal Ready master 2d
Cos’è successo: dopo aver chiesto a OpenShift di eliminare l’istanza, questa non è stata creata nuovamente per rimpiazzare la precedente, perché esattamente come per un Pod in Kubernetes, una risorsa di tipo Machine non ha un meccanismo di ripristino.
Quindi, quando viene eliminata o muore, è morta.
Per fornire la dovuta resilienza alle risorse Machine, è necessario utilizzare un MachineSet, così come avviene tramite l’uso di un ReplicaSet per un Pod).
Quindi, diamo un’occhiata ai MachineSet nell’ambiente:
$ oc get machinesets --all-namespaces
>>>
NAMESPACE NAME DESIRED CURRENT READY AVAILABLE AGE
openshift-machine-api my-cluster-worker-eu-central-1b 3 3 3 3 2d
Dall’output è possibile vedere che ci sono MachineSet per i nodi worker, ma non per il master. A questo punto è facile immaginare che il master sia così configurato perché non abbia bisogno di scalabilità: solitamente nell’architettura di un cluster ce ne saranno sempre -minimo- 3, quindi OpenShift ha deciso di non creare un MachineSet per il master.
Questo vuol dire che attualmente il cluster rimane operativo, ma ci troviamo su un terreno molto rischioso. Se perdiamo un altro master (per qualsiasi motivo), etcd smetterà di funzionare, e di conseguenza OpenShift.
Come ritornare alla situazione precedente? Semplice.
Ricostruiamo il terzo master. Ancora una volta, seguiamo il concetto di Machine per creare l’istanza e avremo bisogno della definizione di una risorsa da poter utilizzare per crearne una nuova. Quindi, eseguiamo i seguenti comandi per creare il file YAML da modificare:
$ oc get machine ip-xxx-yyy-zzz-94.eu-central-1.compute.internal -n openshift-machine-api -o yaml > master-1.yaml
Quindi ora ho un file YAML con la definizione di uno degli altri master, che posso modificare per creare il master mancante.
Sarà sufficiente cambiare il campo metadata.name ed eseguire il seguente comando:
$ oc create -f master1.yaml
Una volta che questo sarà creato, verrà rilevato dal cluster come nuovo nodo master e aggiunto all’infrastruttura:
$ oc get machines --all-namespaces
>>>
NAMESPACE NAME PHASE TYPE REGION ZONE AGE
openshift-machine-api my-cluster-master-0 Running m5.xlarge eu-central-1 eu-central-1b 2d
openshift-machine-api my-cluster-master-1 Running m5.xlarge eu-central-1 eu-central-1b 2d
openshift-machine-api my-cluster-master-2 Running m5.xlarge eu-central-1 eu-central-1b 2d
openshift-machine-api my-cluster-worker-eu-central-1b-xxxxx Running c5.4xlarge eu-central-1 eu-central-1b 2d
openshift-machine-api my-cluster-worker-eu-central-1b-yyyyy Running c5.4xlarge eu-central-1 eu-central-1b 2d
openshift-machine-api my-cluster-worker-eu-central-1b-zzzzz Running c5.4xlarge eu-central-1 eu-central-1b 2d
$ oc get nodes
>>>
NAME STATUS ROLES AGE
ip-xxx-yyy-zzz-10.eu-central-1.compute.internal Ready worker 2d
ip-xxx-yyy-zzz-121.eu-central-1.compute.internal Ready worker 2d
ip-xxx-yyy-zzz-233.eu-central-1.compute.internal Ready worker 2d
ip-xxx-yyy-zzz-193.eu-central-1.compute.internal Ready master 2d
ip-xxx-yyy-zzz-94.eu-central-1.compute.internal Ready master 2d
ip-xxx-yyy-zzz-175.eu-central-1.compute.internal Ready master 2d
Voilà: ambiente ripristinato, con 3 nodi master.
Spiegazione
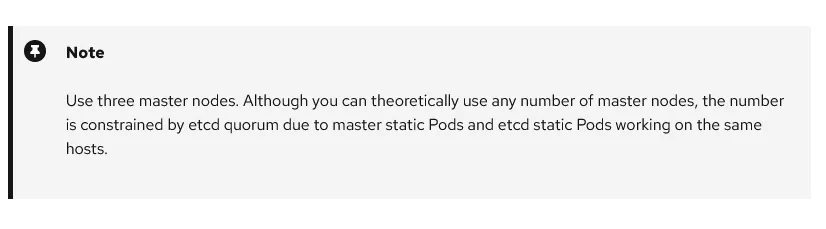
La documentazione dell’architettura di Openshift 4 descrive i master come un gruppo di macchine che non fanno parte di un set di macchine, questa è l’architettura supportata, testata e consigliata. Lo stesso documento afferma che il numero di master deve essere esattamente 3:
Come visto, esiste una procedura di ripristino per sostituire un master in errore con uno nuovo, e questo prevede la creazione del nuovo master come risorsa Machine, anche se potrebbe venire in mente di utilizzare un MachineSet per mantenerne la configurazione e la gestione del numero di repliche. Tuttavia, la configurazione risultante non è ufficialmente supportata da Red Hat, e per diversi motivi.
Avere i master definiti come un MachineSet non offre vantaggi evidenti ma aggiunge ulteriori rischi, per diversi motivi:
- La presenza di più di tre master non è consigliata o supportata, pertanto il ridimensionamento dei master potrebbe causare problemi nel cluster.
- Il ridimensionamento dei nodi master per il ripristino da una situazione di errore di uno di essi richiede comunque l’applicazione manuale della procedura di ripristino di emergenza di cui sopra, pertanto non è possibile alcun ripristino automatico.
- Dopo che il MachineSet di un master è stato ridimensionato e la procedura di ripristino di emergenza è stata
applicata con successo per sostituire un master in errore, a un certo punto il MachineSet dovrebbe essere
ridimensionato per rimuovere la macchina in errore, tuttavia si tratta di un’operazione rischiosa, è necessario
adottare misure aggiuntive per evitare di rimuovere la macchina sana invece di quella guasta.
Test #2
E allora, cosa succederebbe se eliminassimo un worker?
Eseguiamo lo stesso test di prima, ma stavolta eliminiamo uno dei nodi applicativi. Come visto, esistono molti modi per farlo, e andremo a utilizzare la CLI di OpenShift e il concetto di Machine:
$ oc delete machine my-cluster-worker-eu-central-1b-xxxxx
>>>
machine.machine.openshift.io "my-cluster-worker-eu-central-1b-xxxxx " deleted
Ora, se controlliamo nuovamente il numero di Machine, ce ne dovremmo aspettare 2, giusto?
Sbagliato.
Vediamo le Machine:
$ oc get machines -n openshift-machine-api
>>>
NAMESPACE NAME PHASE TYPE REGION ZONE AGE
openshift-machine-api my-cluster-master-0 Running m5.xlarge eu-central-1 eu-central-1b 2d
openshift-machine-api my-cluster-master-1 Running m5.xlarge eu-central-1 eu-central-1b 2d
openshift-machine-api my-cluster-master-2 Running m5.xlarge eu-central-1 eu-central-1b 2d
openshift-machine-api my-cluster-worker-eu-central-1b-xxxxx Running c5.4xlarge eu-central-1 eu-central-1b 2d
openshift-machine-api my-cluster-worker-eu-central-1b-yyyyy Running c5.4xlarge eu-central-1 eu-central-1b 2d
openshift-machine-api my-cluster-worker-eu-central-1b-AAAAA Running c5.4xlarge eu-central-1 eu-central-1b 2m
Dall’ultima riga, noteremo che OpenShift ha creato immediatamente un’altra istanza del worker node, nella stessa zona di disponibilità.
Questo è il potere delle risorse di tipo Machine e dei MachineSets.
Allo stesso modo in cui un ReplicaSet fornisce resilienza a un Pod, un MachineSet fornisce resilienza a una Machine.
Utilizzando il principio Kubernetes dello stato desiderato, un MachineSet dichiarerà quante istanze in una determinata zona di disponibilità vogliamo e quindi, non appena distruggiamo l’istanza corrispondente, il MachineSet distribuirà rapidamente un’altra macchina in AWS e la configurerà come worker node.
Niente male, no?
Risorse utili
- Documentazione ufficiale
- Docker - per cominciare bene con Docker e Kubernetes
- Kubernetes - Guida per gestire e orchestrare i container


