Sistemi di generazione di immagini
Immagini sintetiche: nelle ultime settimane sono usciti moltissimi articoli che parlano di intelligenze artificiali in grado di generare immagini a partire da un testo inserito dall’utente.
Stable Diffusion e DALL-E 2 sono solo due esempi di questi sistemi open source per la creazione di immagini sintetiche: ma come funzionano?
Cosa sono
Sono sistemi che a partire da alcuni front (o testi) generano svariate illustrazioni; essi si basano su un tessuto di deep-learning, prettamente paragonabile al tessuto nervoso umano, contenente oltre 3 miliardi e mezzo di connessioni e capace di generare immagini a partire da una vasta biblioteca di dati.
Chiaramente questo lavoro richiede un addestramento fitto e oneroso, basti pensare che per “insegnare” a un sistema a generare immagini in autonomia servono diverse centinaia di CPU a lavorare simultaneamente.
Soluzioni sul mercato
Il più conosciuto nel settore è DALL-E 2 che, come è facile intuire, è la seconda versione di un precedente sistema omonimo divenuto famoso per la sua capacità di generare immagini in buona qualità. DALL-E 2 genera immagini a partire da un prompt, vale a dire un input.
Questi sistemi di IA sono essenzialmente quasi tutti privati (sì, può utilizzarli il pubblico ma affinché possano poi essere venduti come servizi più completi); difatti, anche i grandi del settore non stanno perdendo tempo: Google ha sviluppato Party e Imagen, ancora in fase di sviluppo, Microsoft sta implementando VQ-Diffusion, META lavora su Make-A-Scene (implementato perlopiù su scenari del metaverso), e un laboratorio indipendente sta sviluppando invece Midjourney.
Fanno eccezione, per la loro caratteristica di essere open source, Crayion e DreamStudio prodotto da Stability.AI.
Come funzionano
Questa rete neurale con cui sono stati costruiti è in grado di imparare a partire dai dataset vastissimi costituiti da immagini associati ad una “didascalia”; in altre parole partendo da una frase genererà la sua relativa illustrazione. Questa tecnica si chiama diffusion e consente la generazione delle immagini. La diffusione in avanti avviene se partiamo da un’immagine a cui aggiungiamo via via più rumore, al contrario la diffusione all’indietro avviene grazie all’intervento dell’IA e parte dal rumore generando, attraverso milioni di esempi contenuti nel dataset, delle illustrazioni, che diventeranno intellegibili grazie all’intervento del prompt.
Spieghiamo meglio: affinché l’immagine generata dal sistema abbia un senso, al rumore dovrà essere associato un input testuale –e in questo caso parliamo di text-guided-diffusion.
Alcuni esempi di immagini generate da Stable Diffusion:
 Alieno
Alieno
Un altro esempio oltre a quelli citati è GLIDE: si tratta di un modello che sfrutta la diffusion basata sul testo condizionale per produrre immagini sintetiche, e che è possibile provare sfruttando Python congiuntamente al repository ufficiale.
Riflessioni
La maggior parte di questi progetti di AI sono stati resi disponibili come progetti open source: questo è un segnale importante nel voler coinvolgere la community per evitare che ci siano potenziali usi impropri di questi strumenti.
In diverse occasioni, sono stati utilizzati per generare immagini che risultano divertenti e anche molto comiche:
 Un corgi con gli occhiali da sole
Un corgi con gli occhiali da sole
 Gatti che sciano (?)
Gatti che sciano (?)
 Coniglio con giacca rossa
Coniglio con giacca rossa
 Sottomarino che legge
Sottomarino che legge
Come in tutte le applicazioni, bisogna considerare che le conseguenze che si hanno nel rendere questi strumenti alla portata di tutti: alcuni utenti si sono infatti detti preoccupati dell’utilizzo di queste risorse per generare immagini che producano deepfake o contenuti pornografici.
Diversi sistemi che generavano immagini di volti di persone sono stati più volte utilizzati per creare profili fake online: l’esempio più conosciuto è quello del sito ThisPersonDoesNotExist.
Alcuni di questi servizi tuttavia sono limitati nel loro utilizzo: l’accesso per testarne la beta version è su richiesta e ha una lista di attesa estremamente lunga, e questo anche per limitarne la diffusione e le potenziali conseguenze negative.
Inoltre, vale la pena valutare la possibilità che questi sistemi possiedano dei bias: inserendo frasi come “doctor at work”, “engineer” o “police” tramite il sito di Stable Diffusion, i risultati sono i seguenti:
 “Doctor at work”
“Doctor at work”
 “Police”
“Police”
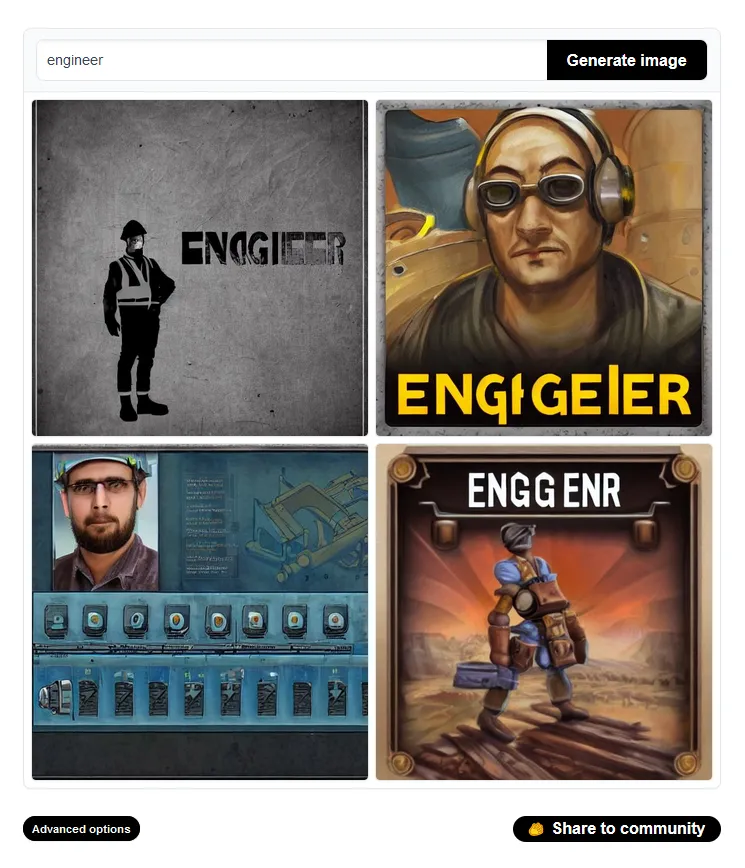 “Engineer”
“Engineer”
Sebbene le capacità dei modelli di generazione di immagini siano impressionanti, possono anche rafforzare o esacerbare i pregiudizi della società. Poiché la maggior parte di questi modelli sono stati addestrati su dati non filtrati recuperati da Internet, è spesso possibile generare immagini che contengono stereotipi.
Come si evince dalla documentazione di questi sistemi, si tratta comunque di un topic al centro dell’attenzione delle persone che sviluppano questi sistemi, e su cui stanno lavorando proattivamente.
Piccola nota: i volti delle persone potrebbero risultare un po’ “strani”: come spiega la documentazione di Craiyon, si tratterebbe di un problema causato dall’encoder delle immagini.
E tu, che ne pensi?
Risorse utili

Articoli Correlati