Table partitioning in PostgreSQL

Se il concetto di ereditarietà permette di creare una relazione tra una o più tabelle, il partizionamento ne consente una suddivisione logica che si adatta meglio alle esigenze di business.
Partizionare la tabella, chiamato table partitioning, significa dividere una tabella in pezzi più piccoli.
Il partizionamento delle tabelle offre molti vantaggi in termini di prestazioni per le tabelle che contengono grandi quantità di dati.
E, indovina un po’? PostgreSQL consente il partizionamento delle tabelle tramite l’ereditarietà delle tabelle.
Ogni partizione viene creata come tabella figlia di una singola tabella genitore.
Un esempio potrebbe essere quello delle prenotazioni effettuate da un’agenzia di viaggi internazionale: tenendo in una tabella unica tutte le prenotazioni eseguite nel corso della sua attività, la lista rischia di allungarsi di molto nel giro di poco tempo.
Per questo, creare delle tabelle partizionate per anno/mese, permette alle persone che vi lavorano di recuperare le informazioni più velocemente, e quindi migliorare anche le prestazioni del database.
Esempio
Riprendendo l’esempio fatto in precedenza, immaginiamo di voler memorizzare le informazioni di tutti i voli prenotati nel corso dell’attività dell’agenzia, con il relativo numero di volo, compagnia, stato del volo e data di prenotazione: creiamo la tabella bookings con queste informazioni.
CREATE TABLE bookings(id serial, flightno int, flightcompany varchar(100), status varchar(100), booking_date timestamp)
Creiamo anche una serie di tabelle che rappresentino i voli per anno e mese, e che ci permettano di suddividere i dati attraverso più “elenchi”, di dimensione ridotta: nella creazione delle tabelle, specifichiamo di creare la tabella esattamente come quella originale, ma con un controllo sulle date inserite:
CREATE TABLE bookings_2023_jan(check(booking_date >= '2023-01-01' AND booking_date <= '2023-01-31')) inherits(bookings);
CREATE TABLE bookings_2023_feb(check(booking_date >= '2023-02-01' AND booking_date <= '2023-02-28')) inherits(bookings);
CREATE TABLE bookings_2023_mar(check(booking_date >= '2023-03-01' AND booking_date <= '2023-03-31')) inherits(bookings);
...
Se usi pgAdmin come client per accedere al tuo database, questo è quello che vedrai nel menù di sinistra: due frecce accanto alle tabelle, dove le tabelle derivate riportano una freccia in entrata per indicare che sono create a partire da quella principale, ossia bookings:
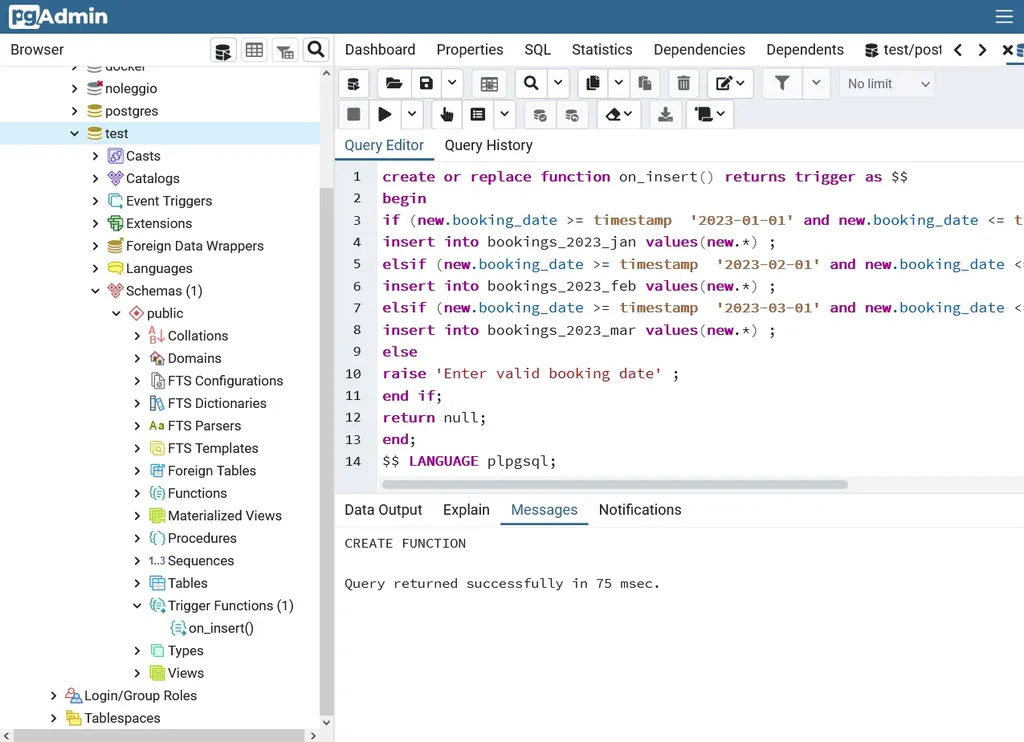
A questo punto, applichiamo un barbatrucco per poter partizionare i nostri dati all’inserimento: creiamo una procedura che, verificati i dati che stanno per essere inseriti all’interno della tabella bookings, procediamo ad inserire i dati nella tabella corretta, secondo la data specificata nel campo booking_date:
create or replace function on_insert() returns trigger as $$
begin
if (new.booking_date >= timestamp '2023-01-01' and new.booking_date <= timestamp '2023-01-31') then
insert into bookings_2023_jan values(new.*) ;
elsif (new.booking_date >= timestamp '2023-02-01' and new.booking_date <= timestamp '2023-02-28') then
insert into bookings_2023_feb values(new.*) ;
elsif (new.booking_date >= timestamp '2023-03-01' and new.booking_date <= timestamp '2023-03-31') then
insert into bookings_2023_mar values(new.*) ;
else
raise 'Enter valid booking date' ;
end if;
return null;
end;
$$ LANGUAGE plpgsql;
All’interno di questa funzione, andiamo a specificare quali sono i controlli da eseguire sul campo booking_date all’interno dell’oggetto denominato new: questo contiene i dati inseriti dall’utente che richiede l’aggiunta di un nuovo record nella tabella, e ne riporta le informazioni principali. Per ogni mese, andiamo a creare un ramo if e terminiamo, eventualmente, con un messaggio di errore, che riporta di creare una prenotazione che segua una data valida tra quelle che si vogliono memorizzare.
Questa funzione è una funzione “speciale”, perché va a restituire un trigger: si tratta di un oggetto che si attiva e scatena delle operazioni non appena vengono rilevate delle azioni particolari. In questo caso, andiamo infatti a creare un trigger che, all’inserimento di un nuovo record nella tabella bookings, vada a richiamare la funzione appena creata, così che i dati vengano correttamente inseriti nella tabella partizione:
create trigger booking_entry before insert on bookings for each row execute procedure on_insert();
Inserimento
Proviamo a inserire dei dati, e vediamo cosa succede:
INSERT INTO bookings(flightno, flightcompany, status, booking_date)
VALUES (12345, 'AirCanada', 'Ontime','2023-01-07');
INSERT INTObookings(flightno, flightcompany, status, booking_date)
VALUES (67890, 'Lufhtansa', 'Ontime','2023-02-16');
INSERT INTO bookings(flightno, flightcompany, status, booking_date)
VALUES (13579, 'Vueling', 'Delayed','2023-03-09');
Riportando l’elenco delle singole tabelle, vediamo che i record sono stati inseriti correttamente:
SELECT * FROM bookings_2023_feb;
>>>
2 67890 "Lufhtansa" "Ontime" "2023-02-16 00:00:00"
Notiamo l’ID del record del mese di febbraio: è pari a 2, e non 1, nonostante sia l’unico della tabella. Questo perché in PostgreSQL, quando si eredita una colonna che ha come tipo di dato serial dalla tabella genitore, la sequenza è condivisa dalla tabella genitore e figlia.
Questo vuol dire che se riprendiamo il concetto di ereditarietà, ci aspettiamo che tutti i record inseriti finora siano 3:
SELECT * FROM bookings;
>>>
1 12345 "AirCanada" "Ontime" "2023-01-07 00:00:00"
3 67890 "Lufhtansa" "Ontime" "2023-02-16 00:00:00"
4 13579 "Vueling" "Delayed" "2023-03-09 00:00:00"
Allo stesso modo, utilizzando l’operatore ONLY, visto nell’articolo dedicato all’ereditarietà, noteremo che la tabella è vuota:
SELECT * FROM ONLY bookings;
>>>
Questo perché la funzione creata in precedenza interviene prima che il record sia inserito in bookings e lo smista nella tabella corretta, portando due vantaggi: i dati sono correttamente partizionati all’origine dell’inserimento, senza la necessità di avere informazioni duplicate, e di conseguenza non si va a riempire la tabella principale di dati che la renderebbero un elefante a 6 gambe.
Risorse utili
🔗 Leggi anche:

Articoli Correlati








