NoSQL Data Modeling: come funziona

La modellazione dei dati (in inglese data modeling) è il processo di creazione di un modello dei dati per un sistema informativo applicando tecniche formali di modellazione dei dati.
Data la varietà di database NoSQL presenti sul mercato, è facile pensare che questo processo sia dipendente dal sistema utilizzato e soprattutto sia superfluo, dal momento che si parla molto spesso di dati non strutturati.
In realtà, esistono diversi approcci che è possibile utilizzare per modellare lo schema dei dati: ad esempio, in Cassandra e DynamoDB, questo processo avviene tramite una modellazione query-driven: l’accesso ai dati e le query eseguite dall’applicazione che userà i dati determinano la struttura e l’organizzazione delle informazioni che vengono poi utilizzate per progettare le tabelle del database.
A differenza di un modello di database relazionale in cui le query fanno uso di join di tabelle per ottenere dati da più tabelle, queste non sono supportate in sistemi come MongoDB o simili, quindi tutti i campi richiesti devono essere raggruppati in un’unica tabella o rappresentati in altri modi.
Usando un approccio basato su query, ad esempio, si elencano tutte le entità e le relazioni come se stessi costruendo un database relazionale. Poi, si definiscono le query richieste da chi utilizzerà la banca dati e si rappresenta il modello logico dei dati.
Infine, si converte il diagramma in tabelle NoSQL, modellando anche le relative relazioni tramite l’incorporamento o la referenziazione.
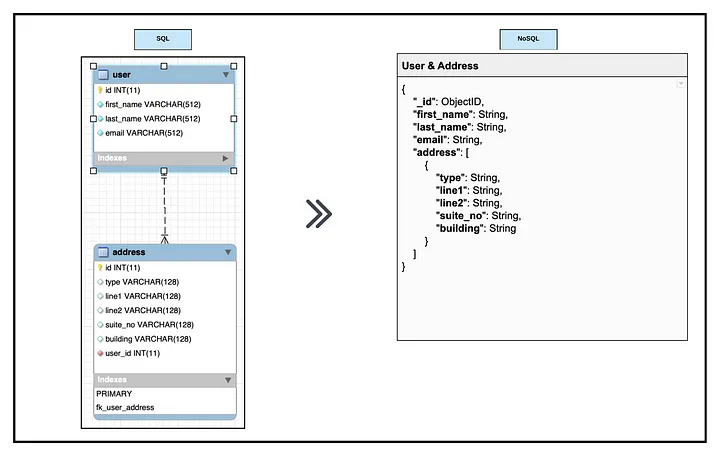
Proviamo a fare qualche esempio: se dovessimo rappresentare un dominio in cui abbiamo degli utenti e i relativi indirizzi, nel contesto di un database relazionale potremmo pensare di disegnare due tabelle, una per ogni entità e stabilire poi una relazione uno-ad-uno dove ad ogni utente è associato un solo indirizzo, e un indirizzo corrisponde ad un solo utente: questo vorrebbe anche dire aggiungere una chiave nella tabella relativa all’indirizzo che riporta, ad esempio, il riferimento all’utente.
Pensando attraverso l’approccio basato su query, se l’applicazione lavora come sistema di censimento degli utenti e delle anagrafiche, possiamo pensare che l’indirizzo dell’utente nel corso del tempo potrebbe variare, e quindi è importante mantenere queste informazioni all’interno del contesto dell’utente.
In un contesto come quello di un database NoSQL, questa relazione può essere rappresentata ugualmente creando una sola collezione che modelli utenti e relativi indirizzi, dove quest’ultimo concetto viene riportato in un array, che è abbastanza flessibile anche nel caso di aggiornamenti, ma soprattutto sappiamo che l’entità relativa agli indirizzi è limitata, e quindi l’array che lo rappresenta non avrà una dimensione eccessiva.
Nel caso in cui volessimo invece rappresentare le informazioni relative ad un e-commerce, quindi composto da utenti con relativi ordini e prodotti, potremo ugualmente pensare di creare un’entità per ogni oggetto del dominio seguendo l’approccio relazionale; poi, seguendo l’approccio query-driven, potremmo pensare che operazioni come la ricerca di un ordine specifico, piuttosto che le informazioni relative ad un prodotto, o ancora la ricerca degli ordini relativi ad un utente sono query che verranno eseguite piuttosto frequentemente.
In questo caso, può quindi essere utile inserire un riferimento all’interno dell’utente che ci interessa nell’ordine, così da recuperare facilmente le informazioni su di esso, e incorporare invece le informazioni più importanti relative ai prodotti di un dato ordine.
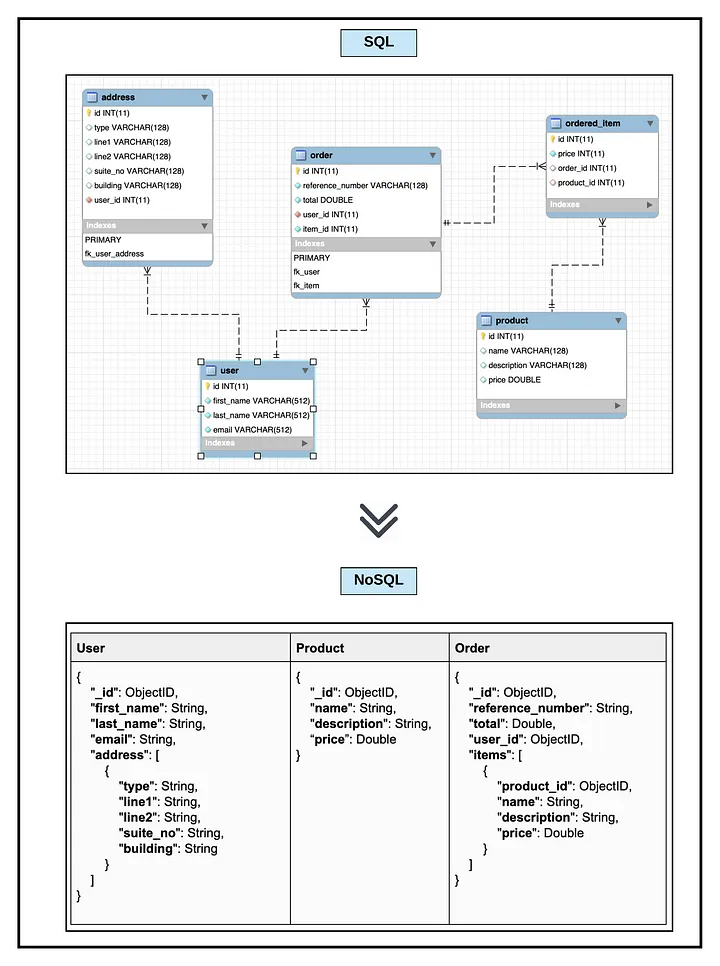
Inserire un riferimento all’interno del documento che ci interessa vuol dire utilizzare un approccio referenziato: questo è il metodo per progettare una relazione normalizzata, dove sia il documento dell’utente che quello dell’ordine verranno mantenuti come due entità separate, ma il documento del primo conterrà un campo che farà riferimento al campo id del secondo.
Questa tecnica è da preferirsi nel momento in cui vogliamo che gli oggetti originali conservino le proprie proprietà e magari abbiano altre relazioni esplicite.
Per il prodotto, l’approccio incorporato invece prevede che la relazione sia rappresentata proprio all’interno del documento stesso. Questo approccio mantiene tutti i dati correlati in un unico documento, il che ne semplifica il recupero e la modifica.
Lo svantaggio è che, se il documento incorporato continua a crescere di dimensioni eccessive, può influire sulle prestazioni di lettura e scrittura del documento principale.
Provenendo da un approccio relazione con il background SQL, molto probabilmente sarà più naturale usare i riferimenti, mentre alcuni potrebbero trovarsi a proprio agio con l’approccio dei documenti incorporati.
Entrambi gli approcci hanno però i loro pro e contro:
- Consistenza: quando si utilizzano i riferimenti, i documenti sono puliti e meno sovraccarichi di informazioni rispetto ai documenti incorporati. Pertanto, abbiamo sempre dei documenti consistenti e indipendenti; questo approccio è peraltro quello più simile a quello dei database relazionali.
- Prestazioni: quando usiamo l’approccio incorporato, abbiamo un unico documento con tutti i dettagli di entrambi i documenti. Uno dei principali vantaggi dell’incorporamento dei documenti è che è possibile caricare sia i dettagli dell’utente che i dettagli dell’indirizzo con una singola query, migliorando così la velocità e le prestazioni di query; tuttavia, i documenti potrebbero sembrare densi di informazioni, specialmente se questi hanno molte proprietà.
Considerando i problemi affrontati in precedenza, quando si sviluppano applicazioni complesse, è probabile che i documenti abbiano molti attributi; in questo tipo di situazioni, è necessario valutare con attenzione l’approccio da adottare, per non avere ripercussioni sulle performance di sistema.
In conclusione? Non complicare eccessivamente una struttura con oggetti estesi e annidati, ma valuta le query che verranno eseguite, contestualmente alla complessità dell’entità che dobbiamo rappresentare.
Le relazioni (1:M) e (M:M) sono più facili da trasformare in un unico insieme se le dimensioni dei documenti sono ragionevoli, come visto negli esempi precedenti.
Inoltre, dividere gli oggetti annidati N volte in collezioni separate è fondamentale, sia per semplicità logica che per le dimensioni.
Infatti, la normalizzazione non è una priorità in NoSQL: la potenza di questi sistemi è data dalla flessibilità. .
Risorse utili
🔗 Leggi anche:

Articoli Correlati






